AMDのZen2「Rome」がIOのみ別チップにした理由 [CPU]
昨日私はAMDによるZen2正式発表に関する記事を書いた。
Zen2のサーバー向けCPU「Rome」が発表される
https://17inch.blog.so-net.ne.jp/2018-11-07
その中でRomeがIOのみ別チップにした理由を、元ネタの記事がエレクトロマイグレーション回避のため、と書いていた事に対し別に理由があるはずだと思った事を“私は理由がそれだけではないと思う”と書いた。
その理由を昨日から考えていたのだが、なんとなく思い付いた事をここに書き留めておく。
その理由は、7nmにプロセスが縮小された事によるダイ面積の縮小により、全てのIOの信号を短くなったダイの端面から出す事が不可能になった事。
昨今はCPUから出るIOの種類が増えている。
昔のCPUはFSBとかシステムバスと呼ばれるデータの通路がCPUから出ていて、CPU以外の全てのデバイスがこれにブラ下がっていた。
これに対し現在は、メインメモリやPCI ExpressからUSBに至るまで、様々なデータの通路が出ている。
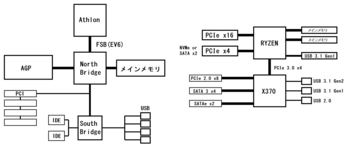
昔と今のCPUから出ているデータバスの違い。昔はFSB一本だけだったが、今は数多くのIOバスが出ている。
こうなるとIOの種類と数の分だけ、ダイの端から線を引き出さなければならない。
AthlonのEV6バスは64bit幅だったので、単純計算で128個の外部接続用パッド(ボンディングでワイヤを接続するための端子)があれば良かった。
しかしZENコアはダイ当たりメインメモリだけで64bitのバスが2本出ている。
これに加えてPCI Expressが合計24レーンで48個、USB3.1が2本で16個。他にこれらに関連する色々な信号もあるはずなのでもっと多くの引き出しポイントが必要だ。これらに加えさらに電源用とかInfinity Fabric用等が加わると、あの小さなダイの短い端面に全ての端子を出すのは無理があるのではなかろうか。
また、Romeの場合8コアのCPUダイを合計8個もCPUパッケージに載せている。
これら8個全てに、PCI Expressなど重複するIOを備えるのは無駄が多すぎる。
だったら共通化出来るIOは全て外に出してしまった方が、CPU本体のダイをコンパクトに出来て良い。
重要なのはInfinity Fabricとメインメモリなので、これだけCPUから出してPCI ExpressやUSBは全部外。
ついでにコアが増えると色々大変になるので、その調停用の機能なんかも全部外に出してしまえばいい。
※追記。どうやらメインメモリのコントローラもIOチップに移動されているようだ。
AMD unveils 64-core Zen 2 CPU, first 7nm GPU
http://cybersecuritycaucus.com/2018/11/amd-unveils-64-core-zen-2-cpu-first-7nm-gpu/
こう考えると、IOだけにしてはやけに大きいCPUパッケージ真ん中のダイも、あの大きさの意味がなんとなく理解出来る。
さらに大きさだけ見れば大容量のキャッシュメモリも載っているかもしれない。
というわけで色々想像で書いてみた。
本当ならば、Romeのブロックダイアグラムを見る事が出来ればそれに全て書かれているはずなので、こんな想像をする必要も無いのだが、私には見つけられなかった。
まあ、私の想像が正しくても間違っていても、ZEZ2コアのRYZENは8コアx2でRomeより小さなIOチップがパッケージされるに違いない。8コア版であれば8コアダイ1個とIOチップ1個の構成になるだろう。
※追記。未確認であるが、ZEN2コアのRYZENは2019年内の販売は予定されていないようである。考えてみれば一般向けのCPUにIOチップ外付けはあり得ない。今回Romeに乗っているダイはサーバー向け専用のダイという事かもしれない。
当然関係者は全て知っているから、仮に私の想像が彼らに知られたら笑われてしまうかもしれないが。
さて、実際はどうなっているのか。
※追記:未確認だが、実際はあくまで製造上の理由のようである。
その内にこの事も公表されるだろうから、その時が楽しみである。
Zen2のサーバー向けCPU「Rome」が発表される
https://17inch.blog.so-net.ne.jp/2018-11-07
その中でRomeがIOのみ別チップにした理由を、元ネタの記事がエレクトロマイグレーション回避のため、と書いていた事に対し別に理由があるはずだと思った事を“私は理由がそれだけではないと思う”と書いた。
その理由を昨日から考えていたのだが、なんとなく思い付いた事をここに書き留めておく。
その理由は、7nmにプロセスが縮小された事によるダイ面積の縮小により、全てのIOの信号を短くなったダイの端面から出す事が不可能になった事。
昨今はCPUから出るIOの種類が増えている。
昔のCPUはFSBとかシステムバスと呼ばれるデータの通路がCPUから出ていて、CPU以外の全てのデバイスがこれにブラ下がっていた。
これに対し現在は、メインメモリやPCI ExpressからUSBに至るまで、様々なデータの通路が出ている。
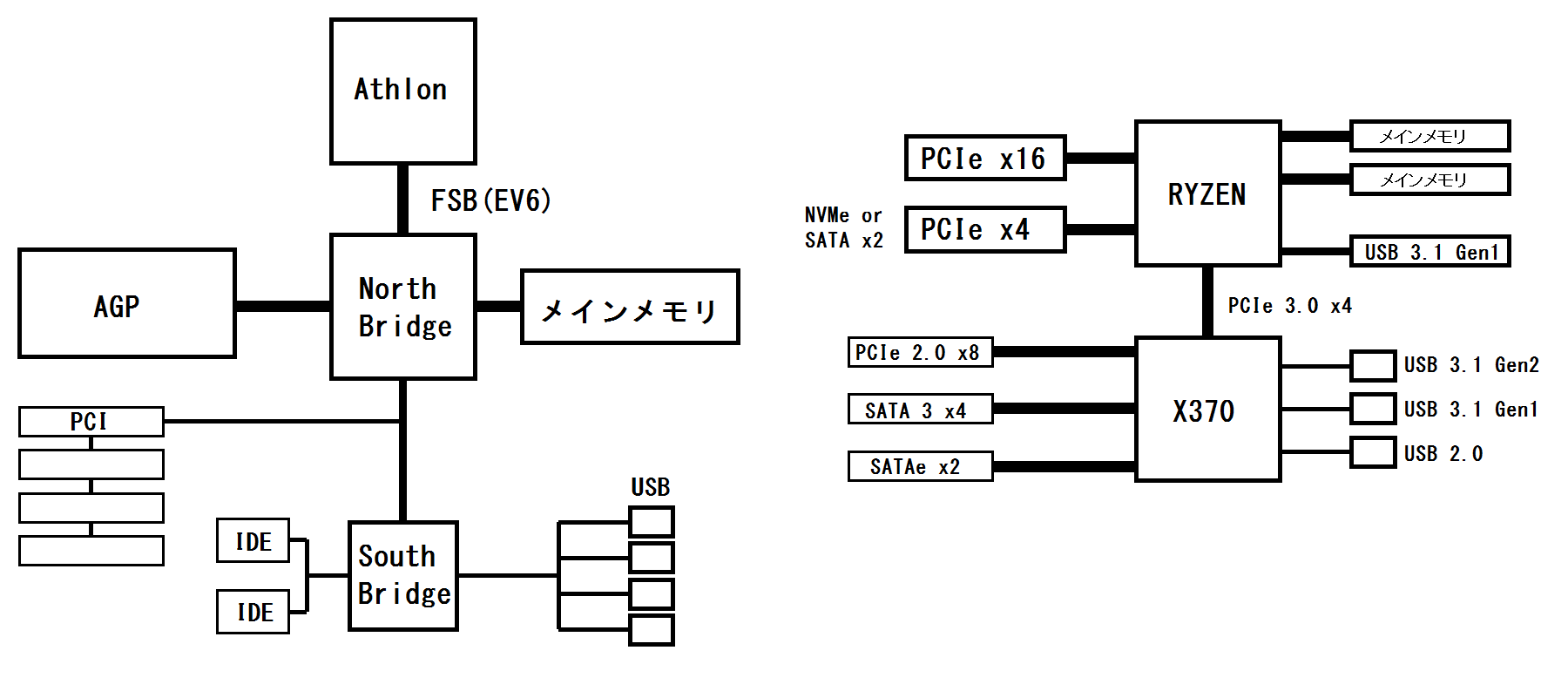
昔と今のCPUから出ているデータバスの違い。昔はFSB一本だけだったが、今は数多くのIOバスが出ている。
こうなるとIOの種類と数の分だけ、ダイの端から線を引き出さなければならない。
AthlonのEV6バスは64bit幅だったので、単純計算で128個の外部接続用パッド(ボンディングでワイヤを接続するための端子)があれば良かった。
しかしZENコアはダイ当たりメインメモリだけで64bitのバスが2本出ている。
これに加えてPCI Expressが合計24レーンで48個、USB3.1が2本で16個。他にこれらに関連する色々な信号もあるはずなのでもっと多くの引き出しポイントが必要だ。これらに加えさらに電源用とかInfinity Fabric用等が加わると、あの小さなダイの短い端面に全ての端子を出すのは無理があるのではなかろうか。
また、Romeの場合8コアのCPUダイを合計8個もCPUパッケージに載せている。
これら8個全てに、PCI Expressなど重複するIOを備えるのは無駄が多すぎる。
だったら共通化出来るIOは全て外に出してしまった方が、CPU本体のダイをコンパクトに出来て良い。
重要なのはInfinity Fabricとメインメモリなので、これだけCPUから出してPCI ExpressやUSBは全部外。
ついでにコアが増えると色々大変になるので、その調停用の機能なんかも全部外に出してしまえばいい。
※追記。どうやらメインメモリのコントローラもIOチップに移動されているようだ。
AMD unveils 64-core Zen 2 CPU, first 7nm GPU
http://cybersecuritycaucus.com/2018/11/amd-unveils-64-core-zen-2-cpu-first-7nm-gpu/
こう考えると、IOだけにしてはやけに大きいCPUパッケージ真ん中のダイも、あの大きさの意味がなんとなく理解出来る。
さらに大きさだけ見れば大容量のキャッシュメモリも載っているかもしれない。
というわけで色々想像で書いてみた。
本当ならば、Romeのブロックダイアグラムを見る事が出来ればそれに全て書かれているはずなので、こんな想像をする必要も無いのだが、私には見つけられなかった。
※追記。未確認であるが、ZEN2コアのRYZENは2019年内の販売は予定されていないようである。考えてみれば一般向けのCPUにIOチップ外付けはあり得ない。今回Romeに乗っているダイはサーバー向け専用のダイという事かもしれない。
当然関係者は全て知っているから、仮に私の想像が彼らに知られたら笑われてしまうかもしれないが。
さて、実際はどうなっているのか。
※追記:未確認だが、実際はあくまで製造上の理由のようである。
その内にこの事も公表されるだろうから、その時が楽しみである。
98式軍刀 さん

-
nice! 863
記事 998
テーマ パソコン・インターネット (18位)
プロフィール
ブログを紹介する



FlipChipパッケージなので端面ではなく面積そのものかと思います
特にEPYC向けともなるとDDR4 8ChにE12G 128x2(Tx/Rx)が主要となりますが、最下配線層へのこの分配となると1ダイでも面積要求がかなり激しい筈です
Zen1世代のMCM方式ではトータルの面積はコレよりも拡大する故にかなり無理があったものと思われます
また、将来的な積層実装も見据えた構成でしょう
by お名前(必須) (2018-11-09 04:50)
お名前(必須)様、コメント有難うございます。
なるほど、今はボンディングワイヤではなくハンダボールをダイ直付けで配線を引き出しているのですね。
考えてみればあのピン数をワイヤで配線というのも、たしかに無理がありますね。
勉強になります。
将来的な積層実装は理解出来るのですが、熱問題はどうなるのでしょうね。
微細化による配線長と抵抗増大による信号の遅延対策でCPUコアの上にキャッシュのSRAMを積層するというのはどこかで読んだのですが、これも上層の配線へ接続する事が難しそうですし。
色々アイデアは多く出ているようですが、なかなか実現は難しいようです。
by 98式軍刀 (2018-11-09 19:41)